

RudderStack rejects the traditional CDP model. Instead of storing your data in another vendor's cloud, it routes everything directly to your own warehouse. For data engineering teams tired of black-box CDPs and vendor lock-in, that architecture appeals. But the platform's strengths also define its boundaries, and this review covers both.
To write this RudderStack review, we analyzed it in detail. We believe it's the right choice if:
You have a data engineering team capable of managing code-based infrastructure
You need real-time event collection routed directly to your own data warehouse
Data ownership and regulatory compliance (GDPR, HIPAA, CCPA) are non-negotiable
You want to build unified customer profiles inside your warehouse, not a vendor's system
You're replacing Segment and need API-compatible migration
However, RudderStack might not be the best choice if:
Your team lacks dedicated data engineering resources
You need a platform that non-technical marketers can operate without engineering support
You want built-in B2B intelligence (contact data, company firmographics, buying intent signals) alongside your behavioral data
You need campaign execution or sales activation tools native to your data platform
You require analyst-validated vendor status for enterprise procurement
RudderStack collects and routes first-party behavioral data. What it does not provide is third-party B2B intelligence: verified contact information, company firmographics, org charts, technographics, and buying intent signals.
This is where ZoomInfo fills the gap: as an all-in-one AI GTM platform with 500M contacts, 100M companies, 135M+ verified phone numbers, and 200M+ verified business email addresses, ZoomInfo provides the B2B intelligence that turns warehouse behavioral data into go-to-market action.
We've included a detailed look at ZoomInfo later in this review because it is the natural complement for teams that need B2B intelligence alongside event data infrastructure. If you're ready to see how ZoomInfo's data can support your go-to-market efforts, start a free trial here.
What is RudderStack?
Source: RudderStack
RudderStack is a customer data infrastructure company founded in 2019 by Soumyadeb Mitra in San Francisco. Mitra, a serial entrepreneur with a Ph.D. in Computer Science from the University of Illinois, built the company after spending a year at 8x8 constructing customer data pipelines. He found that neither DIY builds nor existing CDPs solved the problem of secure, scalable data collection.
The original prototype was open-sourced on GitHub and posted to Hacker News, where it gained early traction as a Segment alternative. The company has since raised $82 million across three rounds, with investors including Kleiner Perkins and Insight Ventures.
RudderStack's core principle: it does not store customer data. All data routes directly to the customer's own warehouse (Snowflake, BigQuery, Redshift, or others).
The product suite includes Event Stream for real-time data collection, Profiles for warehouse-native identity resolution, Reverse ETL for activating warehouse data downstream, Transformations for in-pipeline data modification, and toolkits for data quality and compliance.
As of 2025, RudderStack has delivered 3.3 trillion events for over 4,000 organizations. Companies using it include Crate & Barrel, Allbirds, Grafana Labs, Wealthfront, and HP. In early 2026, RudderStack repositioned itself as the "customer context engine for the AI era", targeting data teams building AI and ML applications that need clean, governed customer data.
The primary buyer is the VP or Director of Data Engineering at mid-market to enterprise companies. RudderStack is built for data engineers and data scientists, not marketers.
RudderStack Pros & Cons
Pros | Cons |
|---|---|
- Warehouse-native: no vendor data storage | - Requires dedicated data engineering resources |
- Open-source data plane available | - Non-technical teams cannot self-serve |
- 200+ pre-built destination integrations | - Destination catalog has gaps for long-tail tools |
- Segment API compatibility for easy migration | - Limited alerting and observability tooling |
- Real-time JavaScript and Python transformations | - Python transformations restricted to Enterprise tier |
- HIPAA, SOC 2 Type 2, and GDPR compliant | - No built-in B2B data or intelligence layer |
- Proven at scale (1B+ events/day at Bol.com) | - No independent analyst recognition (Gartner, Forrester) |
- Permanent free plan with 250K monthly events | - Profiles and SSO locked to Enterprise pricing |
RudderStack Review: How It Works & Key Features
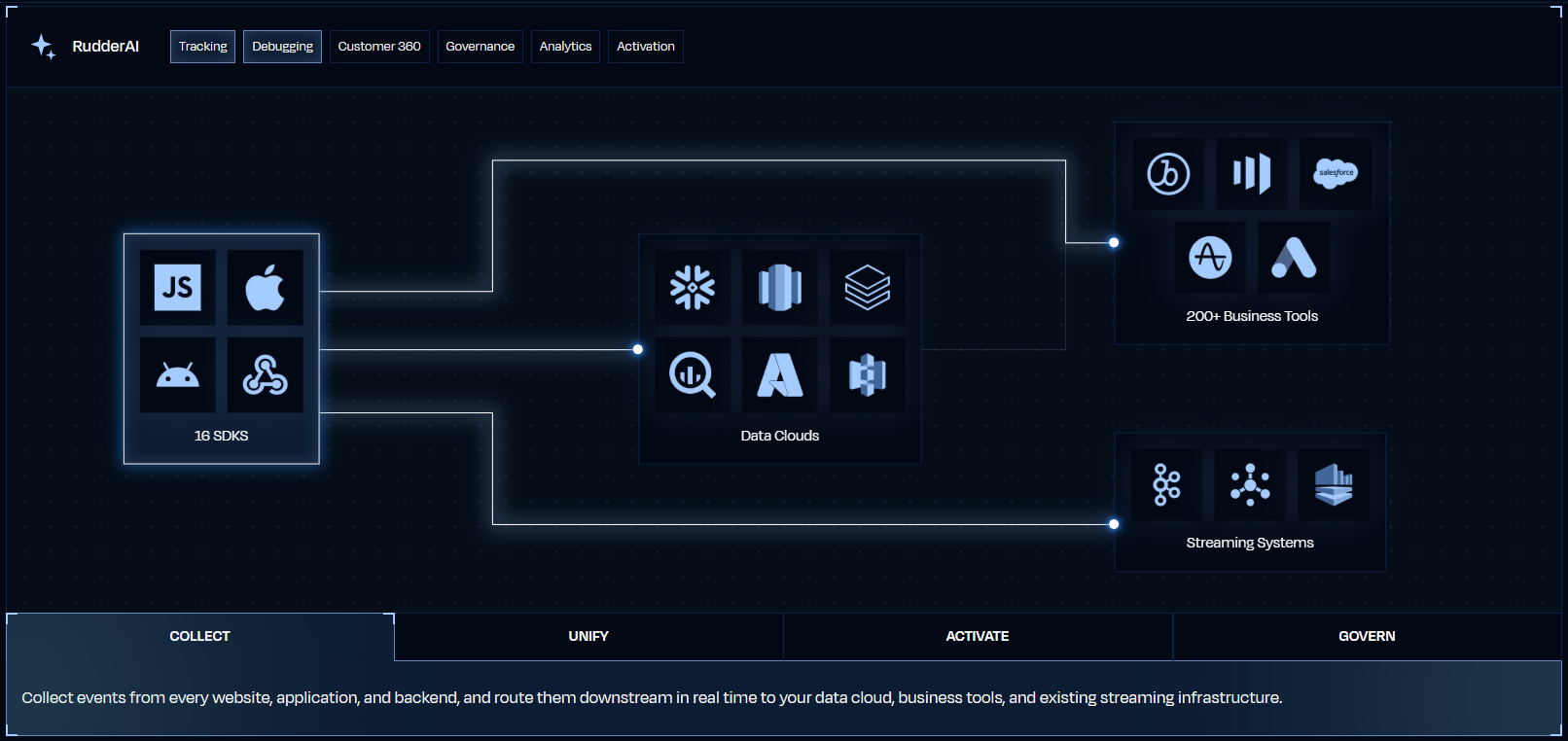
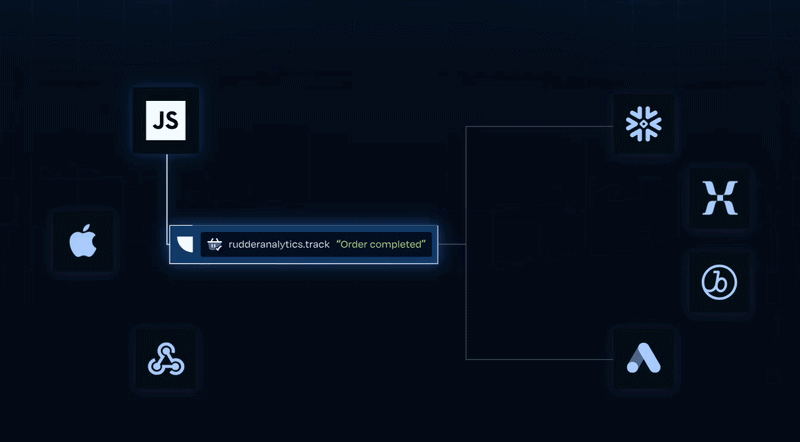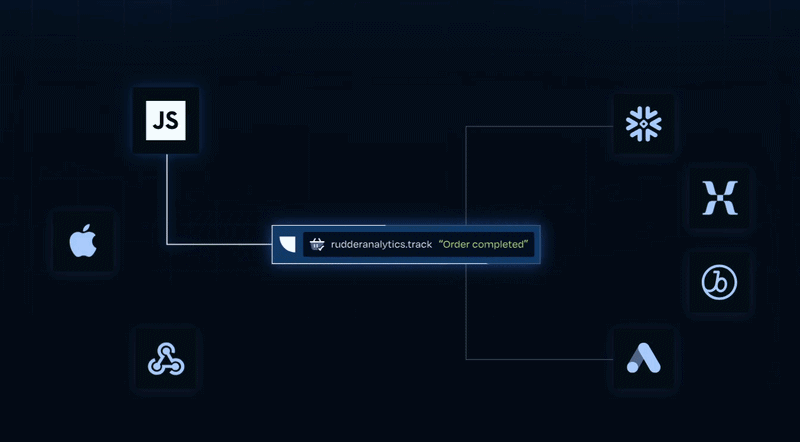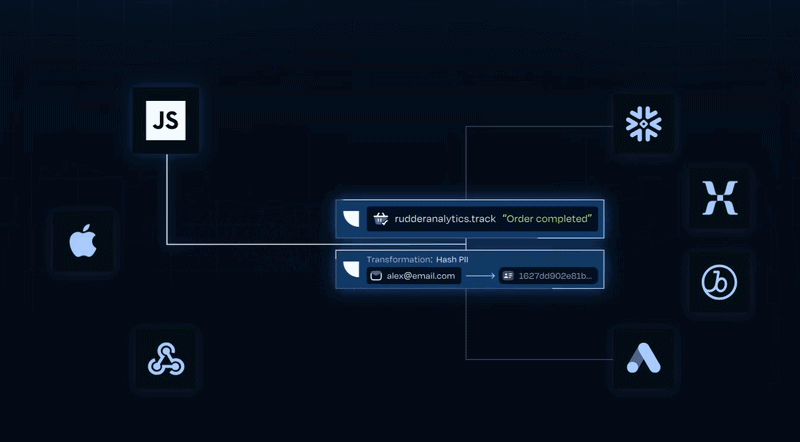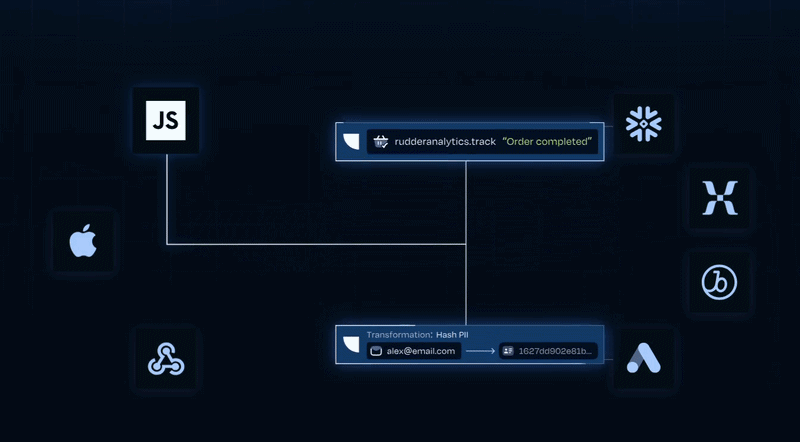
Event Stream: Real-time data collection and routing across 200+ destinations.
Event Stream is RudderStack's core product. It captures behavioral events from web, mobile, and server-side sources, then delivers them in real time to analytics tools, marketing platforms, data warehouses, or streaming systems like Kafka.
Source: RudderStack
The pipeline works in three stages. First, an SDK or cloud source sends events to RudderStack's data plane using a standardized API. The platform provides 16+ SDKs covering JavaScript, iOS (Swift), Android (Kotlin), Flutter, React Native, Node.js, Python, Go, Java, Ruby, PHP, Rust, and others.
Source: RudderStack
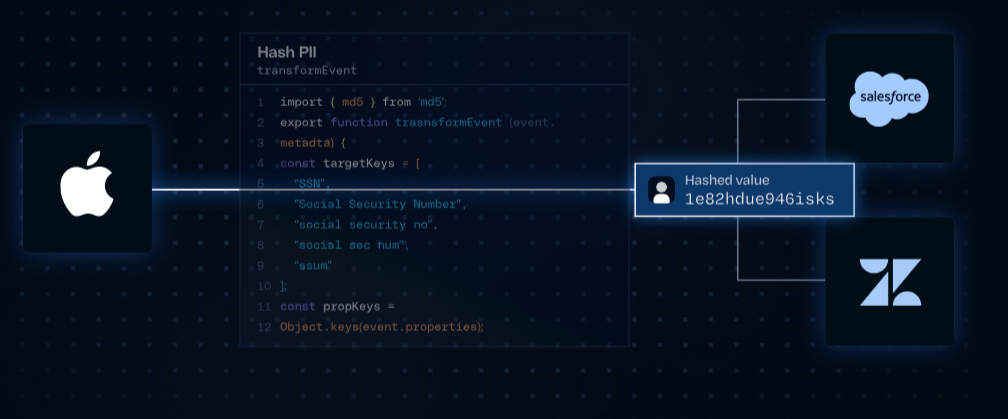
Second, events can pass through real-time Transformations written in JavaScript or Python for enrichment, PII masking, or filtering. Third, the data plane routes events to all configured 200+ destinations.
Destinations support two modes: cloud mode (RudderStack's server calls the destination API) and device mode (the destination's own SDK loads on the client). Other capabilities include cookieless tracking, ad blocker resilient collection, consent management, and event filtering per destination.
Profiles: Warehouse-native identity resolution and Customer 360.
RudderStack Profiles builds unified customer profiles inside your own data warehouse. The problem it solves: a single customer leaves traces across websites, mobile apps, CRMs, and ad platforms, each using different identifiers. Without resolution, data teams end up with siloed, duplicate records.
Source: RudderStack
Profiles operates through four layers. An identity graph stitches together records for the same person, even when they arrive under different identifiers.
A Feature Builder lets teams define computed features (churn scores, CLV, propensity scores) using YAML config files rather than procedural SQL. The output is a set of unified tables in the warehouse that serve as a single source of truth. Activations sync those profiles to downstream tools via Reverse ETL.
Profiles is available only on the Enterprise plan.
Reverse ETL: Activating warehouse data in downstream tools.
Reverse ETL closes the loop between data collection and activation. After data has been centralized, cleaned, and enriched in the warehouse, Reverse ETL delivers it to marketing automation platforms, CRMs, ad tools, and other operational systems.

Source: RudderStack
Users define what to sync by selecting an existing table or writing a SQL model. A Visual Data Mapper lets non-technical users map warehouse columns to destination fields without code. Three sync modes are available: upsert (insert and update incrementally), mirror (keep destination identical to source), and full sync.
Syncs can trigger from Apache Airflow or Dagster workflows, and from dbt Cloud, so they fire only after transformation models finish running. The feature supports 200+ destination integrations and is included on all plans, with unlimited connections starting at the Growth tier.
Transformations: In-pipeline code execution for data quality and enrichment.
Transformations lets engineering teams write custom JavaScript or Python functions that modify event data after collection but before delivery. Over 75% of customers use Transformations, making it one of the platform's most adopted features.
Source: RudderStack
Transformations attach per destination, so the same event can be modified differently depending on where it's going. Functions support async operations, including HTTP fetch calls to external APIs (for example, calling Clearbit to enrich an event before it reaches Salesforce).
The feature is deployable via GitHub with version control, and 19+ quickstart templates cover common use cases like PII masking, IP anonymization, and bot traffic filtering.
JavaScript Transformations are available on all plans. Python Transformations are restricted to Enterprise.
Data Quality and Compliance: Schema governance and privacy controls built into the pipeline.
The Data Quality Toolkit enforces data standards at the point of collection rather than after the fact. Teams define their data state in a centralized Data Catalog, apply Tracking Plans with schema-level rules, and use a Health Dashboard for real-time pipeline monitoring with alerts via Slack, MS Teams, email, or webhooks. Magic Eden saves 72 hours per month previously spent on data cleaning.
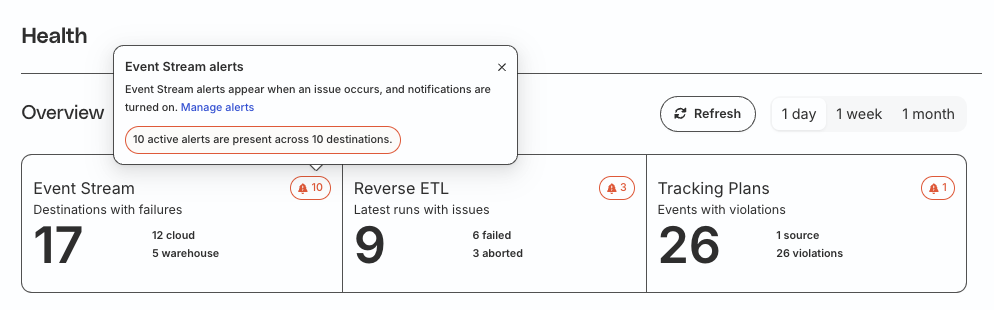
Source: RudderStack
The Compliance Toolkit handles consent management (with integrations for OneTrust, Ketch, and iubenda), PII/PHI controls, and a User Suppression API that propagates deletion requests across the connected stack with a single call. RudderStack holds SOC 2 Type 2, HIPAA (with BAA), and GDPR certifications, and supports separate US and EU data plane regions.
Where RudderStack Falls Short
RudderStack is solid infrastructure for teams with the engineering depth to use it. But several limitations define where the platform stops, and they matter most for organizations trying to connect behavioral data to go-to-market execution.
Engineering-only accessibility. RudderStack is built for data engineers, and that design choice shows on every surface. Transformations require JavaScript or Python code. SQL models for Reverse ETL are managed via CLI with YAML configs.
Profiles require declarative configuration files. TrustRadius reviewers flagged "clunky SDKs requiring additional manual effort" and "lack of automation in deployment processes." Marketing and sales teams cannot self-serve, so every activation request routes through engineering.
No B2B intelligence layer. RudderStack collects behavioral data (page views, clicks, purchases, app events) and routes it to your warehouse. It does not include any third-party B2B data: no contact databases, no company firmographics, no org charts, no technographics, no buying intent signals, and no verified phone numbers or email addresses.
For go-to-market teams, behavioral data alone cannot answer basic questions: who are the decision-makers at accounts showing purchase intent? What's the company's tech stack? Are they researching your category? Filling this gap requires a separate B2B intelligence platform.
No activation or campaign execution. RudderStack can sync data to downstream tools via Reverse ETL, but it has no built-in campaign orchestration, no visual audience builder, and no native messaging layer. Every activation depends on a third-party tool. The platform moves data to the right place, but the "what to do with it" layer lives elsewhere.
Limited alerting and observability. TrustRadius reviewers cited "limited alerting functionality" and "difficulty pinpointing issues with downstream connections." For event-driven architectures where delivery guarantees matter, some reviewers reported occasional outages leading to event loss.
Feature gating on Enterprise. Several capabilities that mid-market teams need (Python Transformations, Profiles, SSO) are locked to Enterprise. Warehouse sync times also vary sharply: 3 hours on Free, 1 hour on Starter, 30 minutes on Growth, 5 minutes on Enterprise. Teams on lower tiers work with real latency disadvantages.
These limitations reflect RudderStack's deliberate focus on data infrastructure over data intelligence or execution. The platform moves first-party behavioral data reliably at scale. But the gap between "data in the warehouse" and "sales rep knows who to call" is wide, and RudderStack does not bridge it alone.
The Natural Complement to RudderStack: ZoomInfo
RudderStack tells you what your prospects and customers are doing. ZoomInfo tells you who they are, how to reach them, and when they're ready to buy. Its GTM Context Graph combines B2B data with your first-party signals to show not just what accounts are doing, but why, and what to do next.
Together, they form a complete data stack: RudderStack as the first-party behavioral backbone, ZoomInfo as the intelligence and execution layer that turns warehouse data into revenue.
Comprehensive B2B Data: The B2B data foundation RudderStack's warehouse needs.
ZoomInfo's B2B data platform covers 500M contacts, 100M companies, 135M+ verified phone numbers, 120M direct-dial phone numbers, and 200M+ verified business email addresses.
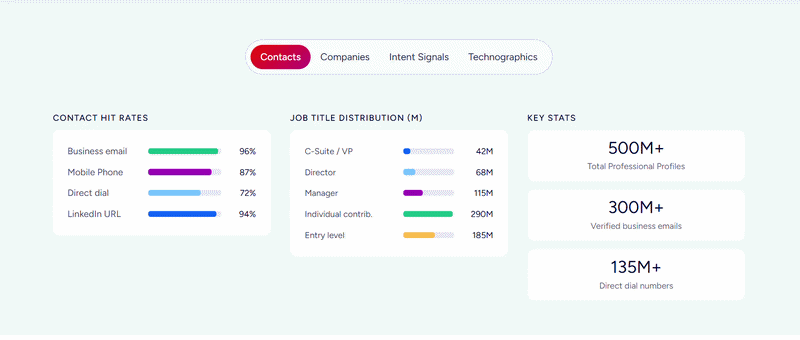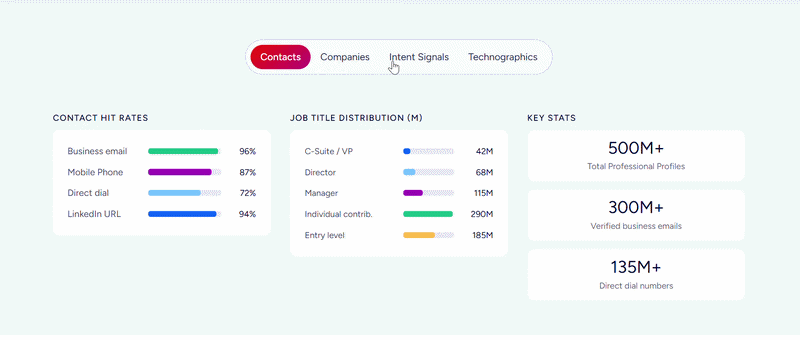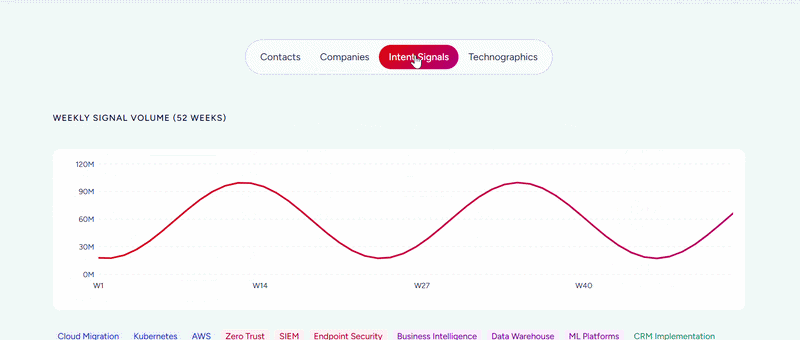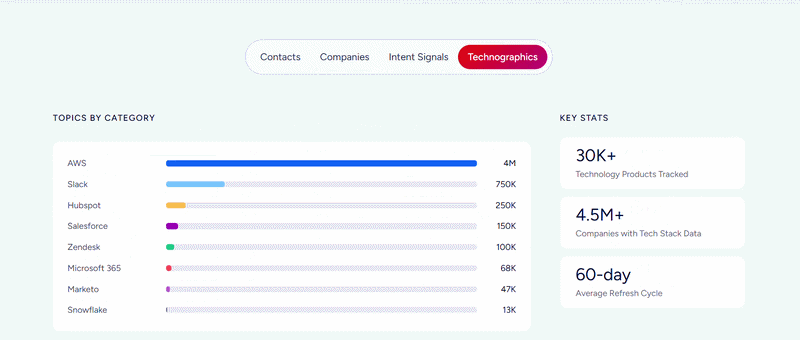
This data spans three dimensions: identity data (who buyers are and how to reach them), company context (firmographics, org charts, technographics covering 30,000+ technologies across 30M+ companies), and signals that show when accounts are in market.
ZoomInfo verifies its data through a multi-source pipeline backed by 300+ human researchers, achieving up to 95% accuracy on first-party data. In a Fortune 500 competitive RFP analyzing 25 million contacts across vendors, the independent consultant concluded that "no other competitor came even close."
For teams using RudderStack, the value is direct. RudderStack can collect that an anonymous visitor viewed your pricing page three times. ZoomInfo can tell you that visitor works at a 500-person company, uses Snowflake, and has been researching your product category for two weeks. One without the other leaves gaps. Together, the behavioral signal and the B2B context create a complete picture.
"ZoomInfo gives us the information we need to execute. We don't have to go through and spend our time digging. It's already there, so we can be three steps ahead." (Vensure)
GTM Context Graph: Intelligence that connects signals to outcomes.
ZoomInfo's GTM Context Graph combines ZoomInfo's B2B data with a customer's own CRM records, conversation transcripts, email interactions, and behavioral signals into a single intelligence layer that processes 1.5B+ data points daily. The difference from a static database: the GTM Context Graph captures not just what happened in a deal, but why.
A CRM records that a deal moved stages. Conversation intelligence captures that the CFO joined the last call and asked about six-month ROI. Intent data shows the company is researching your competitor. The GTM Context Graph connects all three to show why the deal accelerated and what should follow.
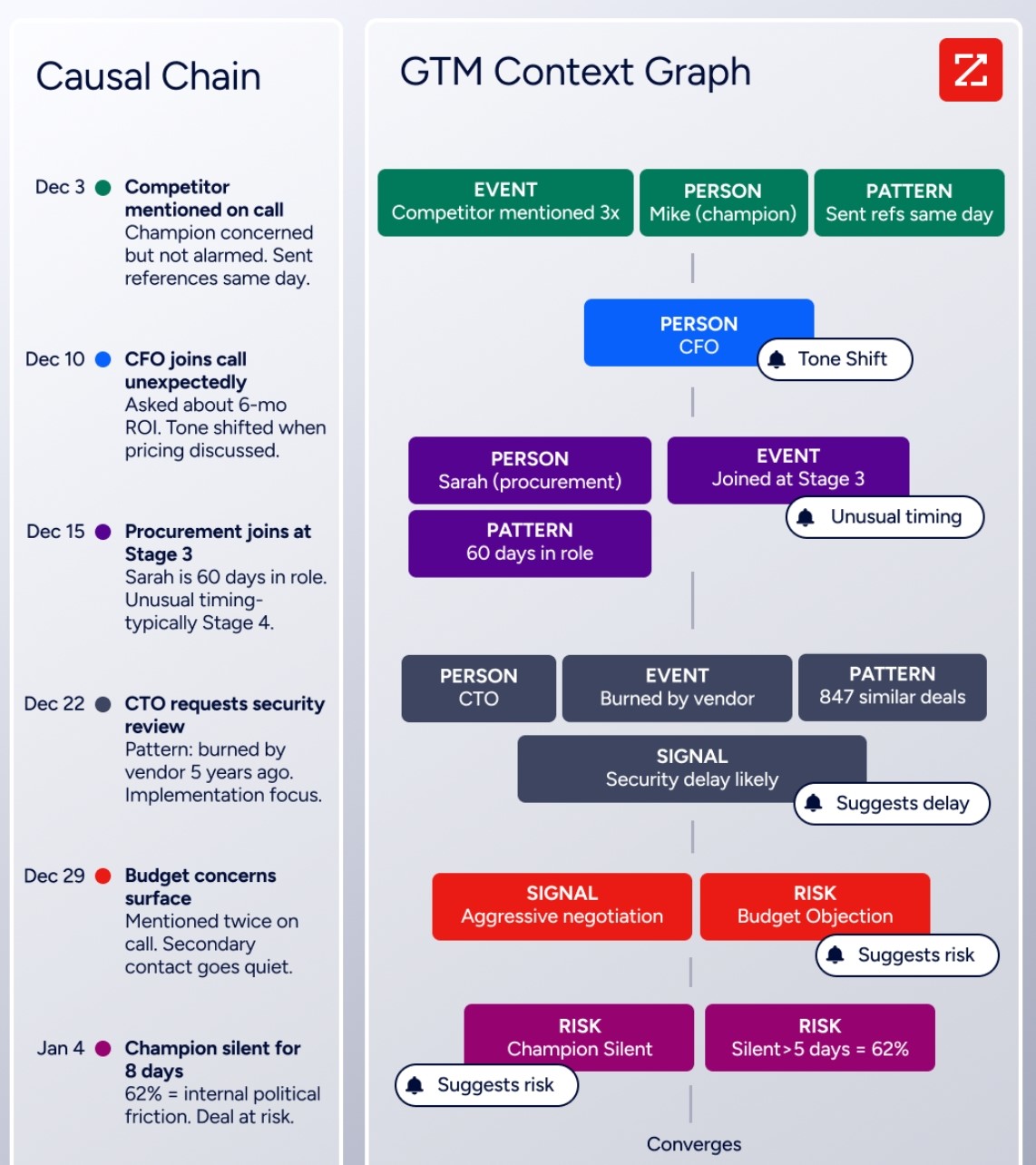
Where RudderStack builds unified customer profiles from behavioral data in the warehouse, ZoomInfo builds contextual intelligence from go-to-market signals. The combination lets data teams use RudderStack to collect and unify first-party events, while revenue teams use ZoomInfo's intelligence to understand what those events mean for pipeline and revenue.
Seismic attributed 39% of active pipeline to opportunities identified or influenced by ZoomInfo signals, with sales teams reporting 54% productivity gains and 11.5 hours saved per week per seller. (Seismic)
Universal Access: APIs, MCP, and native front-ends for every team.
ZoomInfo delivers its intelligence through three channels, which matters for teams already running RudderStack's API-first infrastructure.
APIs and MCP (Model Context Protocol) expose ZoomInfo's data and GTM Context Graph to any custom agent, internal tool, or partner platform.
The MCP server connects AI models directly to ZoomInfo's B2B data as a native tool, currently supporting Claude and ChatGPT. For data engineering teams already comfortable with programmatic access, this fits naturally alongside RudderStack's own API-first architecture.
GTM Workspace gives sellers a single surface where prioritized accounts, AI-drafted outreach, and deal execution converge.
GTM Studio gives marketers and RevOps teams a builder where audience definition, campaign orchestration, and pipeline measurement happen in natural language rather than engineering tickets.
All three channels draw from the same GTM Context Graph: the same data, the same reasoning, the same intelligence, regardless of where a team works.
"The plug-and-play aspect of the API means I can integrate it very easily into any process and get information at a moment's notice," with the team achieving an 87% reduction in time spent on internal data dashboard updates. (BDO Canada)
Data Quality and Compliance: Enterprise-grade verification at the source.
ZoomInfo maintains a certification stack renewed annually: ISO 27001, ISO 27701, SOC 2 Type II, and TRUSTe GDPR and CCPA validations. The company is a registered data broker in California and Vermont.
For teams already investing in RudderStack's compliance toolkits for first-party data governance, ZoomInfo's third-party data carries its own compliance infrastructure. ZoomInfo maintains data freshness through continuous monitoring, with automated ML scanning 28 million site domains daily and nearly 90% of technology pairings updated within three months.
RudderStack and ZoomInfo: Comparison Summary
Aspect | RudderStack | ZoomInfo |
|---|---|---|
Primary Focus | Customer data infrastructure (collection, routing, identity resolution) | B2B intelligence and go-to-market execution |
Data Type | First-party behavioral event data | Third-party B2B contact, company, intent, and signal data |
Core Strength | Warehouse-native event streaming and identity resolution | Verified B2B data and GTM Context Graph |
Target User | Data engineers and data scientists | Sales, marketing, RevOps, and data teams |
Data Storage | No vendor storage; all data in customer's warehouse | ZoomInfo's verified database; API/MCP delivery to any system |
B2B Contact Data | Not included | 500M contacts, 200M+ verified emails, 135M+ verified phones |
Intent Signals | Not included | Buyer intent from 210M IP-to-Org pairings, 6T+ keyword signals |
Campaign Execution | Not included; syncs data to downstream tools | GTM Studio for orchestration, GTM Workspace for seller execution |
Compliance | SOC 2 Type 2, HIPAA, GDPR | ISO 27001, ISO 27701, SOC 2 Type II, TRUSTe GDPR/CCPA |
Free Tier | 250K events/month (permanent) | ZoomInfo Lite (permanent) + 7-day free trial |
Best For | Collecting and routing behavioral data at scale | Providing B2B intelligence to power revenue teams |
Final Verdict
RudderStack and ZoomInfo address two distinct but connected needs in a modern data stack. Treating them as alternatives misses the point; they are complementary layers.
RudderStack excels at collecting, transforming, and routing first-party behavioral data to your warehouse. Its warehouse-native architecture, open-source flexibility, and Segment-compatible migration path make it a strong choice for data engineering teams that want full ownership of their event data pipeline.
If your primary challenge is getting clean behavioral data into your warehouse and syncing it to downstream tools, RudderStack delivers reliably at scale.
ZoomInfo provides the B2B intelligence that turns warehouse data into revenue. When behavioral events show an account is engaged, ZoomInfo identifies the decision-makers, surfaces buying intent signals, maps the org chart, and powers the outreach.
Its GTM Context Graph, built on 500M contacts and 100M companies, captures not just what's happening in your pipeline but why. And with APIs, MCP, GTM Workspace, and GTM Studio, that intelligence reaches every team and every tool.
Get started with ZoomInfo here.
The most effective data stacks combine both: RudderStack as the behavioral data backbone, ZoomInfo as the B2B intelligence layer. One collects the signals. The other tells you who's sending them, why they matter, and what to do next.
RudderStack FAQ
What is RudderStack used for?
RudderStack is customer data infrastructure that collects behavioral events from websites, mobile apps, and servers, then routes that data in real time to data warehouses, analytics tools, and marketing platforms. It also offers identity resolution, reverse ETL for activating warehouse data, and in-pipeline transformations for data cleaning and enrichment.
It is built for data engineering teams, not marketers or sales reps.
Does RudderStack store my data?
No. RudderStack is warehouse-native, meaning it does not store customer data on its own infrastructure. All data routes directly to the customer's own warehouse or data lake (Snowflake, BigQuery, Redshift, Azure Synapse, PostgreSQL, or others). This architecture reduces compliance risk for companies operating under GDPR, HIPAA, or CCPA regulations.
How does RudderStack compare to Segment?
RudderStack launched as an explicit Segment alternative and maintains API compatibility with Segment's SDK and event API, making migration straightforward.
Key differences: RudderStack stores no data in its own systems (Segment uses a proprietary data layer), offers warehouse sync times as fast as five minutes versus Segment's 12+ hours, provides real-time JavaScript and Python transformations, and is open-source. Multiple customers (Kajabi, Apploi, Wyze) have documented smooth migrations, with Kajabi reporting $100K+ in annual savings after switching.
Is RudderStack free?
RudderStack offers a permanent free plan with 250,000 monthly events, 16+ SDK sources, 200+ cloud destinations, warehouse destinations, and Reverse ETL. The free plan has limitations: 3-hour warehouse sync times, only 5 JavaScript Transformations, no tracking plans, and community Slack as the only support channel.
Paid plans start at $220/month for 1 million events on the Starter tier, with Growth and Enterprise tiers requiring custom pricing through sales.
Does RudderStack include B2B contact data or intent signals?
No. RudderStack collects first-party behavioral event data (what users do on your website, app, or product) but includes no third-party B2B intelligence: no contact databases, no company firmographics, no buying intent signals, and no verified phone numbers or email addresses.
Teams that need B2B intelligence alongside their behavioral data use a complementary platform like ZoomInfo, which provides 500M contacts, 100M companies, 135M+ verified phone numbers, and 200M+ verified business email addresses.
Who should use RudderStack?
RudderStack is built for mid-market to enterprise companies with dedicated data engineering teams. The primary buyer is typically a VP or Director of Data Engineering. The platform requires technical fluency: Transformations are written in code, SQL models are managed via CLI, and Profiles uses YAML configuration files.
Companies without data engineering capacity, or teams looking for marketer-operated tools with built-in campaign execution, are not the intended audience.
What compliance certifications does RudderStack hold?
RudderStack is SOC 2 Type 2 certified, HIPAA compliant (with the ability to sign a Business Associate Agreement), and GDPR compliant. The platform supports separate US and EU data plane regions for data residency requirements. Enterprise security features include SSO integration with Okta and OneLogin, SSH tunnels, permissions management, and audit logs.
The zero-data-storage architecture itself reduces compliance surface area, since no customer data resides on RudderStack's infrastructure.
Can non-technical teams use RudderStack?
RudderStack offers some capabilities for non-technical users: the Visual Data Mapper for Reverse ETL, Audiences builder UI, and Profiles Cohorts for pre-defined customer segments. However, the platform's core operations (event instrumentation, Transformations, SQL model management, Profiles configuration) require engineering skills.
Marketing and sales teams generally need data engineering support to build and modify pipelines, create new audience definitions, or troubleshoot data quality issues.