

What is AI data enrichment?
AI and large language models have become go-to tools for go-to-market teams looking to automate complex data tasks. The appeal is obvious: enriching GTM data is intricate, multi-step work that calls on dozens of sources and integrations. Our team recently explored what happens when you hand that work to an LLM, and what we learned is worth sharing.
AI data enrichment is the use of machine learning and large language models to continuously improve business records by inferring missing attributes, resolving conflicts, and classifying entities from unstructured data, going well beyond what traditional data enrichment batch processes can achieve. Where traditional enrichment appends fields on a schedule, AI data enrichment transforms a static database into a living system that learns and evolves as the underlying companies, contacts, and relationships change.
The reason this matters now is straightforward: stale CRM data does not just produce bad outputs in isolation. When AI systems are built on top of it, they amplify and automate flawed assumptions across scoring, routing, and outreach simultaneously. The quality of your enrichment data is a direct multiplier on the ROI of every AI system you build on top of it.
How AI enrichment differs from traditional methods
According to Salesforce State of Sales research, 91% of CRM data is incomplete or inaccurate. That statistic has existed for years, but its consequences have changed. When enrichment ran in quarterly batches and humans reviewed routing decisions, stale data was a friction problem. When AI systems run scoring, routing, and outreach automatically, the same stale data becomes an amplification problem: bad inputs scale at the speed of automation.
The architectural difference between traditional and AI-powered enrichment is not just speed. It is the difference between appending more fields and building a signal-rich data layer that your GTM systems can reason on.
Dimension | Traditional Enrichment | AI-Powered Enrichment |
|---|---|---|
Refresh frequency | Periodic batch (weekly, monthly, quarterly) | Continuous or triggered by CRM flags |
Scalability | Linear cost increase with record volume | Incremental processing on flagged records only |
Accuracy maintenance | Degrades between refresh cycles | Self-corrects as new signals arrive |
Integration complexity | Point-to-point vendor connections | Unified pipeline with normalized output |
Compliance handling | Manual audits at refresh time | Continuous consent signal monitoring |
The strategic shift is from enrichment as a data hygiene task to enrichment as infrastructure. An AI-ready enrichment strategy is about building a signal-rich data layer, not appending more attributes to a record that will be stale again in 90 days.
Identifying the problem: why LLMs alone fall short
Data enrichment AI is a compelling category, but the gap between what LLMs can do and what GTM enrichment actually requires is wider than most teams expect.
Many of our customers are asking the same question: Can we rely solely on LLMs for data enrichment?
It is a fair question. LLMs are becoming increasingly adept at tasks such as identifying mismatching information in large datasets. What this overlooks, however, is that for LLMs to enrich data to the standard required by today's businesses, they need context, and this is where things can start to go wrong if you are relying solely on an LLM.
LLMs can be a useful tool for data enrichment. They can help collect data and evaluate cases, but can struggle to find the right conclusions and actions to take, which is the other half of enrichment. This is because LLMs are not tuned, or sometimes even able, to prioritize the latest data, which is critical for enrichment; they may be able to gather data, but it may not be accurate. Without accurate data, it is impossible to expect LLMs to make correct decisions.
The problem is compounded for RevOps teams managing multiple enrichment vendors with different API contracts and failure modes. Each vendor has its own data format, its own matching logic, and its own way of returning records, with no unified pipeline to reconcile them. When one breaks, the whole enrichment workflow breaks, and the LLM downstream has no way to distinguish a missing field from a genuinely absent attribute.
With that in mind, we set out to see how LLMs could be combined with other tools to achieve more meaningful results.
Real-world use cases for AI data enrichment
The clearest way to evaluate AI data enrichment is to look at where it changes GTM outcomes, not just data completeness scores. Here are five scenarios where AI data enrichment automation delivers measurable operational impact:
CRM enrichment for sales prospecting: Continuous firmographic and contact enrichment triggered by CRM flags rather than batch uploads reduces stale records and improves territory model accuracy. The key pattern here is incremental enrichment: running enrichment only on records flagged as ready-for-enrichment, rather than reprocessing entire databases, reduces compute cost and API call volume while keeping the records that matter most current.
Inbound lead enrichment at the moment of conversion: Enriching form submissions in real time before they hit the CRM or routing logic ensures the first sales touch is informed and fast. When a prospect fills out a form with a personal email address, AI enrichment can resolve the company identity from other submitted fields before the lead enters the routing queue, preventing the misrouting that plagues teams relying on post-submission enrichment.
ABM account scoring: AI enrichment feeds continuous scoring models with fresh firmographic, technographic, and intent signals so ABM programs scale without losing precision. Static scoring models built on batch-enriched data degrade as accounts change; triggered enrichment keeps the inputs current without manual intervention.
Territory and TAM modeling: Enriched data enables territory models that adapt as accounts grow, shrink, or enter your ICP rather than degrading on a stale annual snapshot. For RevOps teams doing territory planning once a year, the underlying data is often wrong by Q2. Continuous enrichment means territory assignments reflect the account universe as it actually exists, not as it existed six months ago.
Lead routing accuracy: Enrichment must run before routing, not after it. When enrichment runs after routing, leads go to the wrong rep and require manual correction, adding 15 to 20 minutes of lag before a qualified prospect hears from anyone. Momentive cut speed-to-lead from 20 minutes to 60 seconds by restructuring their enrichment and routing sequence with ZoomInfo Operations.
Putting the LLM through its paces: what our experiment revealed
Our internal engineering team, led by Anne Fajkus, senior manager of data analysis, recently began exploring ways to combat a data problem our customers commonly encounter: junk CRM data, sometimes so bad that it is difficult to even begin enriching properly.
Fajkus and the team wanted to develop ways of identifying erroneous records on a large scale. Upon closer examination, a potential solution began to emerge.
First, the team took a subset of data, including some of the most common fields we see in CRM data:
Company name
Website
Email domain of known contacts
They also included billing address, which is a useful datapoint for us at ZoomInfo.
Next, the team ran that sample dataset through a custom LLM agent. This gave the team a starting point, by identifying fields that did not match publicly available information.
The agent returned a dataset highlighting where values conflicted with available information, such as apparently incorrect names and addresses.
This is the point at which some companies might call the job done. What this does not offer, however, is insight into why those datapoints are inaccurate, or how to go about reconciling them. We know that there is something wrong with the record, and using an LLM to gather data from, say, a website can highlight that. Part of the problem with this is the fact that not all website data is accurate. Even if it is, this does not help us get to the right action to take because it does not have the correct context to make that decision.
For that context, you need more information, so we turned to ZoomInfo, our all-in-one AI GTM Platform.
Diving deeper with Match Insights
Our matching process includes a feature known as Match Insights, which provides our customers with greater clarity into how their CRM data aligns with ZoomInfo's proprietary database when uploading lists of target accounts.
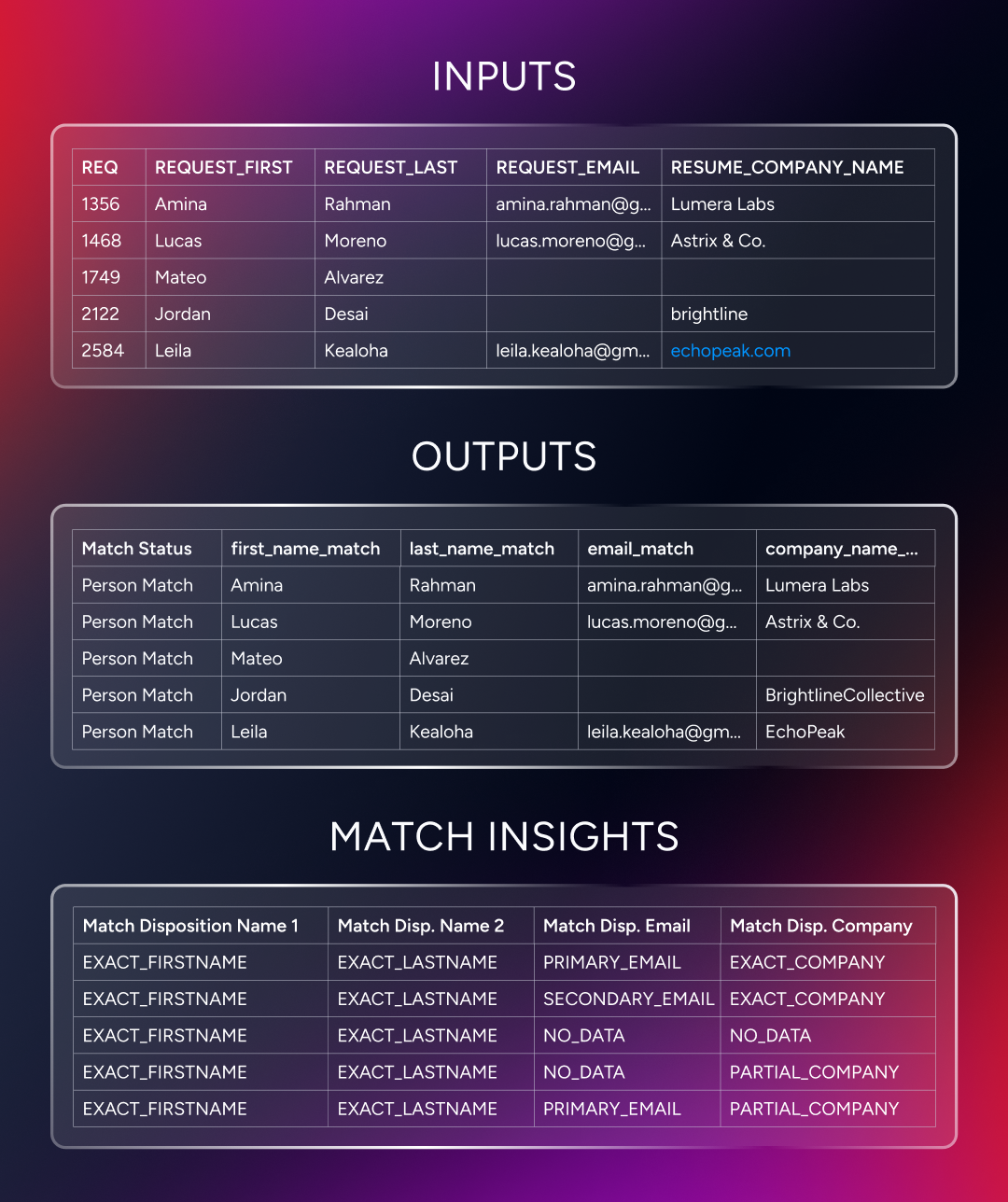
Match Insights gives our customers complete transparency into exactly why certain records matched, partially matched, or did not match at all.
This includes everything from obvious, significant discrepancies between an organization's name and its primary website domain, to subtle differences such as conflicting address information. This helps our customers better understand and refine their data inputs for optimal accuracy and gives them greater confidence in their validation efforts.
When we ran our sample dataset through ZoomInfo's Match Insights, it gave us a strong indication of where potential data decay was present, and served as a guidepost for refinement.
For example, some entities in our sample dataset matched on several fields, such as website, majority email domain, and billing address, but did not match on company name. Upon closer examination, that particular example revealed two distinct company names, both of which matched several other fields, including billing address.
Cross-referencing this with information in ZoomInfo's Hierarchy tab, it became evident that the entity in question had actually rebranded from one name to another, which accounted for the partial matches to the other values.
The team's approach here mirrors best-practice incremental enrichment: processing only flagged records rather than reprocessing entire databases. This pattern reduces compute cost and maintains freshness at scale, and it is the same AI data enrichment automation logic that makes continuous enrichment viable for organizations with millions of accounts.
Learning from history
Many companies realize the data in their CRM is not entirely trustworthy. The problem is what to do with that problematic data.
Should it be purged, or merged? Is a website domain conflict a rebrand, or a redirect? How do you go about determining why a hierarchical relationship changed?
Even the best LLMs need specific direction to return useful results, and those blind spots make even crafting suitable prompts for an LLM deceptively difficult. How do you know what to ask the LLM to do if you do not know where to start?
ZoomInfo has been helping businesses go to market for nearly two decades. During that time, we have acquired many companies, each of which brought their own data that had to be integrated into our master databases. Beyond that, we have an extraordinary advantage in that we have been collecting historical data for the past two decades, not just from our acquisitions' books of business, but from our data pipelines and the work of our 300+ human researchers throughout that time. The breadth of that historical data creates really robust profiles in the present, but also gives us a lot of context about the past. Differentiating what is currently accurate versus what was accurate at one point in time is where LLMs can struggle.
Let us take a look at how this plays out.
If you prompt an LLM to find out who is on ZoomInfo's executive team and how to contact them, much of the information returned is outdated and incorrect, for both ZoomInfo's executive leadership and our board of directors. In addition to presenting outdated information on who these people are, many of the contact emails provided are also incorrect, following a formatting convention that only applies to Henry Schuck, our Chief Executive Officer.
This perfectly demonstrates how LLMs work. LLMs do not actually know anything. They are not answering your question; they are only providing the most likely sequence of words based on your question.
This is why even the latest LLM models get something as fundamental as ZoomInfo's executive leadership team incorrect. If you examined ZoomInfo's public filings over a several-year timeframe, many would name our former COO because he held that position for many years. To the LLM, it looks like the most likely answer. What is worse is that this information is publicly accessible today. As a publicly traded company, our most recent regulatory filings include accurate information on our executive team and board of directors, which, in theory, is available to LLMs including ChatGPT.
Even in an exercise as limited in scope as this, the limitations of LLMs for data enrichment start to become readily apparent.
Challenges and risks in AI data enrichment at scale
Building enrichment workflows on AI infrastructure introduces failure modes that batch-enrichment teams have not had to manage before. Here are four risks worth planning for:
Data staleness amplification: Stale enrichment data does not just produce bad outputs in isolation. AI systems amplify it, automating flawed assumptions across scoring, routing, and outreach simultaneously. A lead scoring model trained on incomplete firmographics does not just score one lead incorrectly; it scores every lead incorrectly, at scale, until someone catches the drift. Mitigation: implement continuous, triggered enrichment rather than periodic batch refreshes so the data layer stays current as the underlying accounts change.
AI model drift from bad inputs: Enrichment models trained or grounded on inconsistent CRM data, including duplicate records, non-standard job title formats, and conflicting address data, inherit and scale those inconsistencies. The model does not know the input is wrong; it learns the pattern and reproduces it. Mitigation: audit and normalize the data foundation before automating enrichment workflows. The garbage-in-garbage-out principle does not disappear when you add AI; it accelerates.
Compliance and data privacy risk (GDPR/CCPA): AI enrichment that appends contact attributes from third-party sources must respect consent signals and data residency requirements. When evaluating AI data enrichment tools for enterprise pipelines, look for vendors with named compliance certifications: ISO 27001, ISO 27701, SOC 2 Type II, and TRUSTe GDPR/CCPA. ZoomInfo holds all four. These are baseline requirements for enterprise data pipelines, not differentiators.
Compute cost of full-database enrichment: Reprocessing entire databases on every enrichment cycle is cost-prohibitive at scale. A 40,000-account CRM with monthly full-refresh enrichment is doing 480,000 enrichment calls per year, most of them on records that have not changed. Mitigation: use incremental enrichment triggered by CRM flags to process only changed or flagged records, reducing compute cost and API call volume while maintaining freshness where it matters.
How ZoomInfo approaches AI data enrichment
ZoomInfo's approach to AI data enrichment rests on three foundations: the most comprehensive B2B data platform, the GTM Context Graph intelligence layer, and universal access across every workflow and tool.
The data foundation is where enrichment quality starts. ZoomInfo's B2B database covers 500M contacts and 100M companies, verified continuously by a combination of automated systems and 300+ human researchers. That verification infrastructure is what separates enrichment that resolves conflicts from enrichment that just appends more fields. Snowflake saw 90% higher opportunity rates and 2x customer conversion on ZoomInfo-scored accounts, a result that traces directly to the quality of the underlying data driving their scoring models.
The GTM Context Graph is the reasoning layer that sits above the data. It processes 1.5B+ data points daily, fusing ZoomInfo's B2B data with customer CRM records, conversation intelligence, and behavioral signals into a unified intelligence layer. For enrichment purposes, this means the platform does not just append a job title; it understands how that contact fits into an account's buying group, what signals suggest the account is in-market, and how the account's hierarchy has changed over time. That context is what makes AI-powered enrichment actionable rather than just complete.
Universal access means that same verified data and intelligence reaches every workflow. For RevOps and GTM engineering teams, GTM Studio is the codeless enrichment and orchestration product that directly addresses the engineering bottleneck problem. Instead of writing SOQL queries, building flows in sandbox, and waiting two weeks for change management, teams can build enrichment workflows, territory models, and routing logic in GTM Studio without engineering tickets. Teams that want to wire ZoomInfo's verified data into their own AI agents or LLM-based tools can do so through MCP or one API, connecting ZoomInfo's B2B intelligence to any agent in their stack. For teams running AI automations at scale, that access flexibility means enrichment happens where the workflow lives, not just inside ZoomInfo's interface.
See how ZoomInfo enriches your CRM data in real time, request a demo.
How to evaluate AI data enrichment platforms
The experiment our team ran illustrates a broader evaluation principle: LLM-based enrichment without a verified data foundation fails on the criteria that matter most for GTM operations. Here is a rubric for evaluating AI data enrichment tools against the requirements that actually drive outcomes:
Data freshness and refresh frequency: How often is the underlying database verified and updated? Batch-only vendors introduce structural lag between refresh cycles, meaning the data you are enriching against may already be stale when you run the job. Look for platforms that support continuous or triggered enrichment so records update as changes occur, not months later.
Coverage depth for your ICP: Does the platform cover the firmographic, technographic, and intent signals relevant to your target accounts? As a benchmark: ZoomInfo's database covers 500M contacts, 100M companies, and 30,000+ technologies tracked across 200+ categories. Coverage gaps in your ICP segment mean enrichment returns empty fields on the records that matter most.
CRM and MAP integration: Does the platform integrate cleanly with your existing stack without custom middleware? Salesforce and HubSpot are the baseline. If integration requires a custom connector or a dedicated engineering sprint, that is maintenance debt that compounds every time either platform updates its API.
Compliance certifications: For enterprise and EU-market teams, ISO 27001, ISO 27701, SOC 2 Type II, and TRUSTe GDPR/CCPA are table stakes for any AI data enrichment platform handling contact data at scale. Treat the absence of any of these as a disqualifier for enterprise pipelines, not a negotiating point.
AI-specific capabilities: Can the platform infer missing attributes, perform entity matching, and ground AI agents with verified B2B context? The GTM Context Graph processes 1.5B+ data points daily, which is what AI-scale enrichment infrastructure looks like in practice. A platform that can only append fields from a static database cannot support the reasoning layer that AI scoring and routing models require.
The ZoomInfo team's own experiment demonstrated exactly this: LLM enrichment without a verified data foundation failed on data freshness, coverage depth, and AI-specific capabilities. The LLM could identify conflicts but could not resolve them, because resolution requires current, verified context that a training corpus cannot provide. An AI solutions for GTM enrichment evaluation should treat those three criteria as the minimum bar, not aspirational features.
Frequently asked questions
What is AI data enrichment?
AI data enrichment uses machine learning and large language models to improve existing business records by adding intelligent, contextual information, going beyond cleaning or normalizing to infer missing attributes, score leads, and classify entities from unstructured text. It differs from traditional batch enrichment, which runs on a fixed schedule and produces a static snapshot, and from data augmentation, which expands synthetic datasets for model training. For a deeper grounding in the concept, see what is data enrichment.
Why do LLMs return outdated contact information?
LLMs predict the most likely sequence of words based on their training data; they do not retrieve current information. They are not tuned to prioritize the latest data, so they surface the most statistically common answer from their training corpus, which may reflect information that was accurate years ago. This is why AI data enrichment built on LLMs alone requires a verified, continuously updated data foundation to produce reliable results.
How does ZoomInfo's Match Insights feature work?
Match Insights provides transparency into how CRM records align with ZoomInfo's proprietary database when uploading lists of target accounts, showing exactly why records matched, partially matched, or did not match at all. It surfaces discrepancies from obvious conflicts (company name versus website domain) to subtle ones (conflicting address data), helping teams understand and refine their data inputs for optimal enrichment accuracy. See how Snowflake's enrichment outcomes demonstrate the downstream impact of accurate enrichment on opportunity rates.
How do I connect ZoomInfo data to an AI agent or LLM workflow?
ZoomInfo exposes its B2B intelligence to any AI agent or LLM workflow through two access paths: the ZoomInfo MCP server for Claude, custom agents, and other MCP-compatible tools, and a single API for programmatic access. Both paths connect to the same verified data foundation covering 500M contacts, 100M companies, and 1.5B+ data points processed daily, so agents are grounded in current, accurate B2B context rather than stale training data.
What causes CRM data decay and how do you fix it at scale?
CRM data decays because companies change: people leave, organizations rebrand, addresses shift, and hierarchies restructure, while most CRM systems only capture point-in-time snapshots. Salesforce research puts the incompleteness rate at 91% of CRM records. Fixing it at scale requires continuous enrichment triggered by CRM flags rather than periodic batch refreshes, so records update as changes occur rather than months later. See CRM data quality for a deeper look at the structural causes and remediation approaches.
Is AI data enrichment GDPR and CCPA compliant?
AI data enrichment can be compliant with GDPR and CCPA when the enrichment vendor maintains proper consent signals, data residency controls, and third-party audit certifications. When evaluating AI data enrichment tools, look for ISO 27001, ISO 27701, SOC 2 Type II, and TRUSTe GDPR/CCPA certifications as baseline requirements for enterprise data pipelines. ZoomInfo holds all four certifications.