

What data deduplication means and why it matters
Data deduplication is the process of removing redundant information from databases and lists so that each entity or record exists only once. This may involve merging or removing extra records, as well as ensuring all information is correctly populated in each field of the record.
While the details of this work will vary based on your tools and processes, the general idea is to compare blocks of data, looking for matches. Metadata is then attached to any data identified as redundant, and the duplicates are placed in backup data storage. This metadata is important because it provides a way of tracking down any removed data, in case any of it needs to be reviewed or retrieved.
Then, indirect matches are flagged for a second review to determine whether the information can be combined into a single record.
In plain terms, data deduplication means keeping only one copy of each record and removing or merging the rest. For a B2B CRM, that means one contact record per person, one account record per company, and one source of truth for every downstream workflow that depends on that data.
Here is what that looks like in practice: a prospect fills out a form with a personal email address, an SDR creates the same contact manually after a cold call, and the prospect's company is then imported from a webinar list under a slightly different company name. The result is three records for one person. Every routing rule, scoring model, and outreach sequence now fires in triplicate, and each copy carries different field values. Data deduplication identifies these as the same entity, merges them into a single golden record, and removes the redundant copies.
Data deduplication is one of the core components of go-to-market data orchestration, the practice of gathering, unifying, organizing, and storing data from various sources in a way that makes it easily accessible and ready for use by GTM teams.
The end-to-end data orchestration workflow includes the following steps:
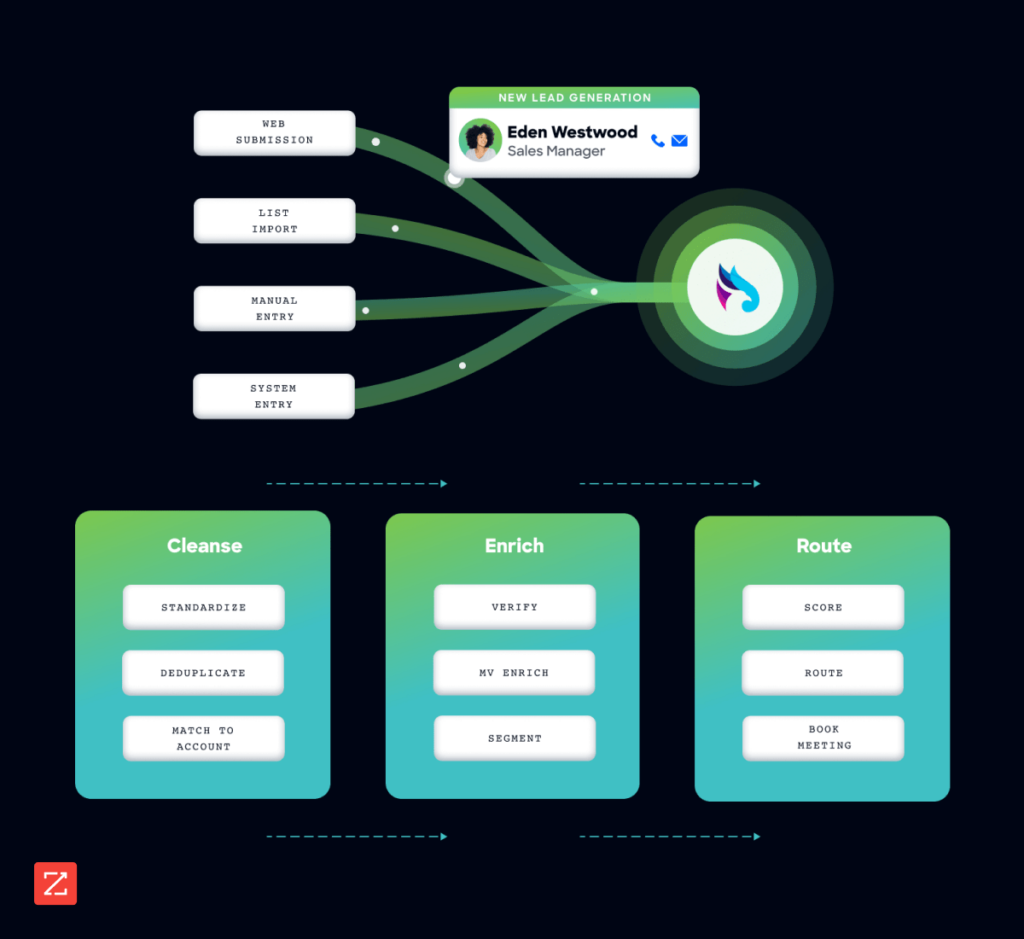
Types of data deduplication: inline, post-process, and beyond
The type of deduplication you choose affects compute cost, bandwidth consumption, and, most critically, when duplicates get caught. Catching a duplicate at the point of record creation is fundamentally different from finding it three months later during a batch cleanup. For RevOps and IT teams, that timing decision has real consequences for pipeline integrity and storage costs.
Deduplication Type | When it runs | Compute overhead | Bandwidth impact | Best for |
|---|---|---|---|---|
Inline | Before data is written | High | Low | Real-time CRM ingestion, web form processing |
Post-process | After data is stored | Low | High | Batch CRM cleanup, legacy data migration |
File-level | Compares whole files | Low | Low | Document storage, email archives |
Block-level | Compares fixed-size chunks | Medium | Medium | Backup and disaster recovery |
Byte-level | Compares byte patterns | High | Low | Maximum precision, primary storage |
The more precise the deduplication process, the more compute power it requires. For most B2B CRM environments, inline deduplication at the point of record creation, combined with post-process batch cleanup for legacy data, is the most practical combination.
Data deduplication is not the same as data compression. Compression reduces redundancy within a single file by re-encoding its contents. Deduplication identifies identical chunks across large volumes of data and replaces them with a single shared copy. They are complementary techniques, not interchangeable ones.
The hidden cost of duplicate data
Duplicate records aren't merely an IT inconvenience. They represent a fundamental business problem with far-reaching consequences.
When multiple versions of the same customer exist in your systems, your sales teams waste time pursuing already-engaged prospects, marketing campaigns deliver contradictory messages to the same recipient, and executives make decisions based on artificially inflated metrics.
According to IBM research, poor data quality costs U.S. organizations $3.1 trillion annually, with duplicate records identified as a primary contributor. An Experian Data Quality study found that businesses suspect approximately 22% of their customer and prospect data is inaccurate, leading to wasted resources and missed opportunities.
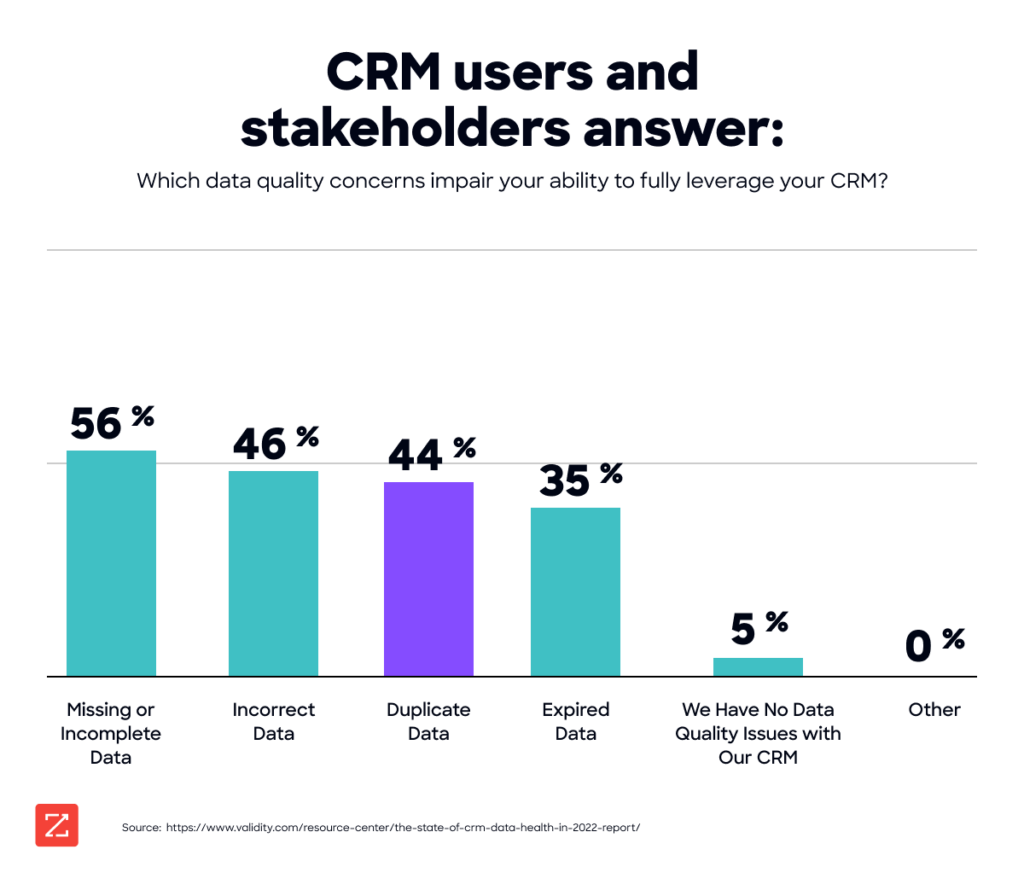
This isn't just inefficient. It's unsustainable in a competitive marketplace where data accuracy provides critical competitive advantages.
The downstream damage compounds when AI and automation enter the picture. Every scoring model, routing rule, and outreach sequence built on a CRM with duplicate records inherits those errors and amplifies them at scale. A lead-routing workflow that fires twice for the same contact doesn't just waste a rep's time. It signals to the prospect that your organization doesn't know who they are.
The sections below put specific numbers to that damage, drawn from teams that have lived through it.
What duplicate data actually costs your GTM team
The cost of duplicate data isn't abstract. It shows up in specific, measurable places across your GTM stack.
Three named customer outcomes illustrate the pattern:
Speed-to-lead (Momentive): Momentive compressed speed-to-lead from 20 minutes to 60 seconds after cleaning its data routing layer, a 20x improvement that came directly from eliminating the enrichment-before-routing gap that duplicate records create.
CRM data completeness (Sendoso): Sendoso reduced inaccurate data by 70% after consolidating onto ZoomInfo's enrichment pipeline, which also unlocked expansion revenue opportunities that were invisible in the dirty data state.
Duplicate record removal (Watermark Insights): Watermark Insights removed duplicate records at scale, restoring the data foundation that territory models and scoring workflows depend on.
Without deduplication governance, teams pay to store, enrich, contact, and market to the same record multiple times across different tools and workflows. Every duplicate record is a tax on your enrichment budget, your outreach volume, and your AI model accuracy.
Data deduplication use cases: CRM, backup, and beyond
Data deduplication applies across every layer of the modern data stack, but the stakes and mechanics differ significantly by use case.
1. CRM and customer data deduplication (B2B RevOps)
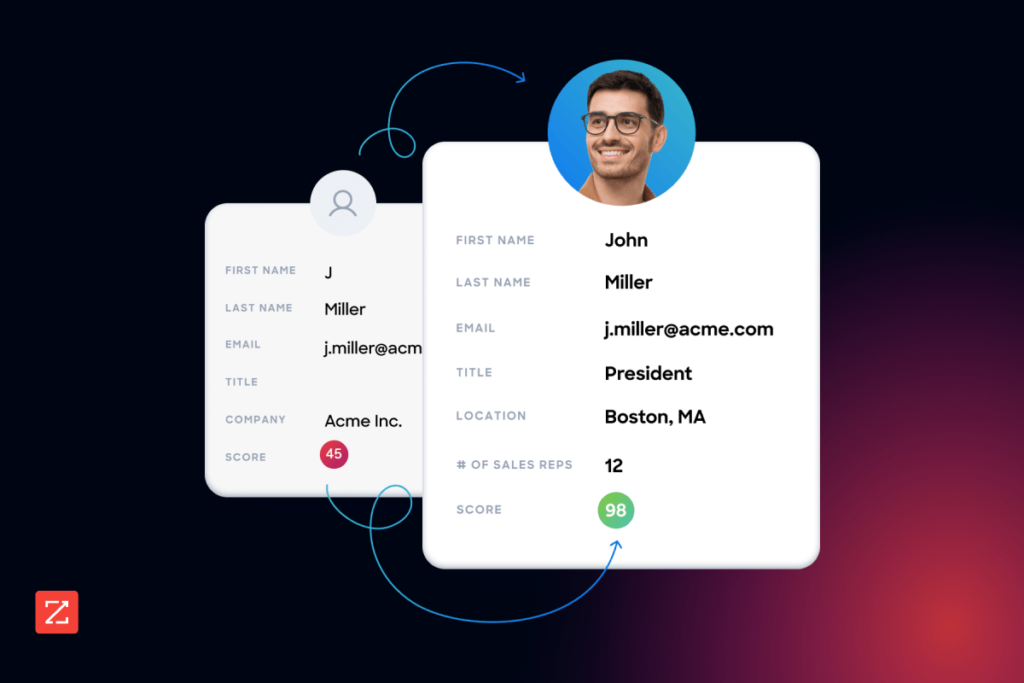
This is the highest-stakes use case for GTM teams. Duplicate contact and account records corrupt lead routing, inflate pipeline metrics, and break AI scoring models. Customer data deduplication in a B2B CRM context means establishing a single golden record per person and per company that all downstream workflows can trust.
Four ingestion pathways create the majority of CRM duplicates: form fills with personal email addresses, manual SDR record creation, webinar list imports without matching rules, and sales tool pushes under variant company names. Each pathway requires a different matching strategy. Personal email submissions need company-name fuzzy matching to link the record to the right account. Manual SDR creation requires search-before-create enforcement. Webinar imports need domain-based deduplication to catch variant company names before they create new accounts.
Account deduplication adds a layer of complexity when corporate hierarchies are involved. A regional subsidiary and its parent company may share the same domain but represent distinct go-to-market relationships. CRM data deduplication logic that flattens these into a single record destroys territory and routing data that was correct. The deduplication system needs to understand not just whether two records share a field value, but whether they represent the same buying relationship.
2. Salesforce data deduplication
Salesforce is the most common CRM in enterprise GTM stacks, and its native deduplication tools, Duplicate Rules and Matching Rules, are limited in scope. They catch exact-match duplicates but miss fuzzy matches, variant company names, and records that entered through API integrations. Salesforce data deduplication at enterprise scale requires an external enrichment and deduplication layer that normalizes records before they enter the system, not after. Teams that rely solely on native Salesforce deduplication consistently find that a significant share of their duplicate problem lives in the gaps those rules don't cover.
3. Backup and disaster recovery
For IT and storage teams, deduplication reduces the storage footprint of backup workloads by eliminating identical data blocks across backup jobs. A typical backup environment can achieve deduplication ratios of 10:1 to 50:1 for virtual machine workloads, meaning 10 to 50 TB of logical data stored in 1 TB of physical space. The deduplication ratio is the core metric for evaluating storage efficiency in backup environments: higher ratios mean lower physical storage costs and faster backup windows.
4. Cloud storage and archiving
Cloud storage costs scale with volume. Deduplication reduces the data transferred and stored in cloud environments, directly reducing egress and storage costs. The impact is most significant for email archives, document management systems, and log data, where the same files and content blocks appear repeatedly across users and time periods.
Understanding the root causes: data introspection
Before building a fix, RevOps teams need to distinguish between account deduplication challenges, where corporate hierarchies and parent-child relationships create apparent duplicates, and true record redundancies that corrupt routing and scoring. Before implementing solutions, organizations must understand why duplicates manifest in their systems. This process of data introspection reveals four common reasons:
Definitional Ambiguity: Many organizations lack clear definitions of what constitutes a duplicate. Is duplication determined at the location level or account level? Without a designated owner of this definition, inconsistent interpretations proliferate across departments.
False Duplicates: What appears to be duplication may actually represent different aspects of a complex corporate relationship. Without proper company hierarchy structures in place, separate locations of the same enterprise might be misidentified as duplicates.
Logical or Permitted Duplicates: Some apparent duplicates exist by design due to legitimate business requirements, perhaps for compliance reasons or to accommodate special account rules. These exceptions must be recognized as intentional rather than problematic.
True Duplicates: These are genuine redundancies resulting from inadequate governance processes. Without "search before create" protocols or data enrichment mechanisms, users continuously generate new records instead of leveraging existing ones. This happens because reps cannot find the correct existing account in the CRM and create a new one, causing internal territory conflicts and broken lead routing that surface only after the damage is done.
Risks and limitations of data deduplication
Deduplication is not risk-free. Understanding the failure modes before implementation prevents the kind of data loss that turns a cleanup project into a recovery project.
Compute overhead for inline deduplication: Inline deduplication adds latency to every record write operation. In high-volume CRM environments, such as large-scale form fill processing or bulk API imports, this overhead can slow ingestion pipelines if the matching logic is not optimized.
False-positive merges: Aggressive matching rules can merge records that represent distinct entities, a regional subsidiary incorrectly collapsed into its parent, or two contacts with the same name at different companies merged into one. False-positive merges are often harder to reverse than the original duplicates.
Index corruption risk: Deduplication systems maintain an index of unique data chunks. If that index is corrupted or lost, the system may be unable to reconstruct the original data from the deduplicated store. Backup validation and index redundancy are non-negotiable for production environments.
Logical duplicates misidentified as true duplicates: Some apparent duplicates are intentional, separate records for a company's headquarters and a regional office, or distinct contact records for the same person in different buying roles. Deduplication logic that does not account for legitimate business rules will destroy data that was correct.
Enrichment-deduplication sequencing errors: When enrichment runs after routing instead of before it, leads are routed on incomplete data and then enriched after the fact, meaning the routing decision was made on the wrong record. This is the most common operational failure mode in enterprise CRM pipelines.
Deduplication is safe when implemented with proper governance controls: metadata tagging of removed records and backup storage before merges are finalized. Human review checkpoints for ambiguous merges and enrichment-before-routing sequencing are the two controls that prevent the most common failure modes.
Building a strategic framework for duplicate management
The failure modes above share a common thread: they stem from missing governance, not missing tools. Effective duplicate management requires more than occasional data cleansing projects. It demands a comprehensive approach integrating people, processes, and technology.
Discovery and baseline establishment
Transform anecdotal complaints about duplicates into concrete, actionable examples. This baseline assessment helps quantify the scope of duplication and distinguishes between necessary exceptions and problematic redundancies. Remember: de-duplication isn't the ultimate goal. It's the natural result of good data management practices.
Cluster and organize
Bring order to data chaos by clustering your account information into logical groupings. Leverage corporate hierarchies to associate locations with their ultimate parent companies. This organizational structure helps identify which records represent distinct entities within the same corporate family versus actual duplicates requiring consolidation.
This clustering process serves a dual purpose: it immediately improves data usability while simultaneously establishing principles for ongoing governance. By analyzing these clusters, patterns emerge that inform your organization's definition of duplication and appropriate management responses.
Leverage third-party data partners
Platforms like ZoomInfo bring an authoritative external reference layer to your deduplication logic, built on 500M verified contacts and 100M companies, that lets you match records against a continuously updated reference layer rather than a static CSV. By matching your records against authoritative external databases, you can more confidently identify and merge duplicate entries into "golden records," the most accurate and complete representation of each customer relationship.
ZoomInfo's GTM Context Graph actively reasons across your CRM records and external signals to surface golden-record candidates with confidence that rule-based matching alone cannot achieve.
Implement search-before-create protocols
To stop the proliferation of duplicates at the source, establish mandatory search processes before new record creation. This simple yet effective practice ensures users first locate existing records before generating new ones. When bypassed, implement decision points requiring justification for creating apparent duplicates.
Data stewards play a crucial role in enforcing these protocols while balancing efficiency with compliance. Their oversight ensures adherence to established data governance principles without creating excessive friction in business processes.
Align with business requirements
Successful duplicate management requires understanding the business purpose behind each record. Different departments may have legitimate reasons for maintaining separate customer records, such as tracking distinct business relationships or complying with differing regulatory requirements.
By collaborating closely with business users, data teams can align management practices with operational needs, rather than imposing technically perfect but functionally problematic solutions. This collaborative approach builds organizational buy-in while ensuring data structures support rather than hinder business objectives.
Protect and enrich continuously
Maintaining data quality requires ongoing vigilance. Implement processes to continuously validate and enhance your customer information, keeping records updated and complete. Data orchestration tools, combined with third-party enrichment services, can automatically refresh information, reducing the likelihood that outdated records will prompt users to create duplicates.
When enrichment runs before routing, not after, leads reach the right rep with complete firmographic context, compressing the window between inbound capture and first touch.
This continuous enrichment approach shifts the paradigm from reactive cleanup to proactive quality management, dramatically reducing the resources required for data maintenance while improving accuracy.
How ZoomInfo eliminates duplicate data at the source
ZoomInfo is an all-in-one AI GTM Platform built specifically to address the root causes of duplicate data, not just clean up after them.
ZoomInfo's data foundation covers 500M contacts and 100M companies, verified by 300+ human researchers with up to 95% accuracy on first-party data. When your CRM records are matched against this continuously updated reference layer, the system can identify which records represent the same entity with confidence that rule-based matching alone cannot achieve. The result is a golden-record candidate surfaced from authoritative external data, not a probabilistic guess from internal field comparisons. For RevOps teams dealing with CRM data deduplication at scale, this means the matching logic is grounded in a verified identity graph, not a static export.
The GTM Context Graph goes beyond field-level enrichment. It processes 1.5B+ data points daily, fusing your CRM records with conversation intelligence, behavioral signals, and org hierarchy data to reason across your account universe. For deduplication, this means the system understands not just that two records share a domain, but whether they represent the same buying relationship, the same territory, or a legitimate parent-child account structure that should be preserved.
GTM Studio gives RevOps teams a codeless interface to build enrichment, deduplication, and routing workflows without engineering tickets. CRM data deduplication that previously required a two-week engineering cycle, SOQL queries, sandbox testing, change management, can be configured and launched in an afternoon. The same platform handles waterfall enrichment from 25+ sources, lead routing, and territory assignment, consolidating what was previously a multi-vendor stack into a single auditable pipeline.
Request a demo to see how ZoomInfo's data foundation and GTM Studio workflows eliminate duplicate records before they corrupt your routing and scoring models.
How to choose a data deduplication solution
Not all deduplication solutions are built for the same problem. A storage deduplication appliance and a CRM data quality platform solve fundamentally different challenges. Before evaluating options, RevOps teams should work through six criteria that separate solutions built for their environment from ones that will create new maintenance debt.
Inline vs. post-process: Does the solution catch duplicates at the point of record creation (inline) or clean them up in batch after the fact (post-process)? Inline prevention is more valuable for active CRM environments; post-process cleanup is necessary for legacy data migration.
Matching logic depth: Does the solution support exact-match only, or does it handle fuzzy matching, domain-based normalization, and variant company names? Rule-based matching misses the majority of real-world duplicates in enterprise CRMs.
CRM and MAP integration: Does the solution connect natively to your CRM (Salesforce, HubSpot, Microsoft Dynamics) and marketing automation platform (Marketo, Pardot, HubSpot Marketing) without custom middleware? Integration complexity is the most common source of new maintenance debt.
Enrichment coverage: Does the solution enrich records as part of the deduplication process, or does it only identify and remove duplicates? A solution that enriches while deduplicating produces golden records, not just fewer records.
Auditability and governance: Can RevOps teams review and approve merge decisions, or does the system merge records automatically without a human checkpoint? Automated merges without audit trails create compliance risk and make it impossible to distinguish intentional duplicates from true redundancies.
Scalability without engineering tickets: Can marketing and sales teams build and modify deduplication and routing workflows without opening an engineering ticket? The operational velocity cost of engineering dependencies is often larger than the cost of the duplicates themselves.
For teams evaluating customer data deduplication software, GTM Studio addresses all six criteria in a single platform. It handles inline deduplication at record creation, supports fuzzy matching and domain-based normalization, integrates natively with Salesforce and HubSpot, enriches records as part of the deduplication workflow, provides full audit trails for merge decisions, and enables RevOps teams to build and modify workflows without engineering handoffs. For teams that have been managing data deduplication tools across multiple vendors, consolidating onto a single platform also reduces the API contract surface and the failure modes that come with it.
Taking action: your path to duplicate-free data
Momentive compressed speed-to-lead from 20 minutes to 60 seconds by cleaning its data routing layer. Watermark Insights removed duplicate records at scale to restore the data foundation its territory models depended on. Both outcomes came from the same starting point: establishing a baseline, assigning ownership, and implementing at least one preventative measure within 30 days.
To begin your journey toward duplicate mastery:
Conduct a rapid assessment of your current duplication rates and their business impact
Establish clear ownership of data quality within your organization
Develop consensus definitions of duplicates specific to your business context
Implement at least one preventative measure (like search-before-create) within the next 30 days
Create a roadmap for developing more sophisticated capabilities over time
Frequently asked questions
What is data deduplication in CRM systems?
Data deduplication in CRM systems is the process of identifying and removing or merging redundant contact and account records so that each person and company exists only once in the database. In a B2B CRM, duplicates typically enter through form fills, manual SDR record creation, list imports, and sales tool integrations. The goal is a single golden record per entity that all downstream workflows, including routing, scoring, enrichment, and outreach, can trust. CRM deduplication is a foundational step in any data orchestration strategy because a deduplication failure upstream corrupts every workflow that depends on the data.
What is an example of data deduplication?
A common CRM example: a prospect fills out a web form with a personal email address, an SDR creates the same contact manually after a cold call, and the prospect's company is imported from a webinar list under a slightly different company name. The result is three records for one person. Data deduplication identifies these as the same entity, merges them into a single golden record, and removes the redundant copies. For storage environments, the classic example is email attachments: 100 employees each saving the same 1 MB file creates 100 MB of storage; post-deduplication, only one copy is stored and 99 references point to it, reducing storage to 1 MB.
Is data deduplication safe?
Data deduplication is safe when implemented with proper governance controls: metadata tagging of removed records so they can be retrieved if needed, backup storage of deduplicated data before merges are finalized, human review checkpoints for ambiguous or high-risk merges, and sequencing that runs enrichment before routing. The primary risks are false-positive merges, where two distinct entities are incorrectly collapsed into one, and index corruption, where the deduplication system loses track of which records were merged. Both risks are mitigated by maintaining a pre-merge backup and auditing merge decisions before they are applied to production data.
What is the difference between data deduplication and data enrichment?
Data deduplication removes redundant records so each entity exists only once. Data enrichment adds missing or updated information to existing records, including firmographics, contact details, technographics, and intent signals. The two processes are complementary: deduplication first establishes a clean record foundation, then enrichment fills in the gaps. Running enrichment on a database with duplicate records wastes enrichment credits and produces conflicting data across multiple records for the same entity.
How do search-before-create protocols reduce CRM duplicates?
Search-before-create protocols require users to search for an existing record before creating a new one. When a rep is about to add a new contact or account, the CRM prompts them to confirm no matching record already exists. This prevents the most common source of true duplicates: reps who cannot find the correct existing account and create a new one, causing internal territory conflicts and broken lead routing. The protocol is most effective when combined with fuzzy matching that surfaces near-matches, including variant company names and different email formats, not just exact duplicates.
How does ZoomInfo help with CRM data deduplication?
ZoomInfo's GTM Studio provides a codeless interface for building enrichment, deduplication, and routing workflows without engineering tickets. Its data foundation, covering 500M contacts and 100M companies verified by 300+ human researchers, serves as the authoritative reference layer for matching CRM records against external identity data to surface golden-record candidates. The GTM Context Graph reasons across CRM records, org hierarchy signals, and behavioral data to distinguish true duplicates from legitimate parent-child account structures. Momentive used ZoomInfo's data routing capabilities to compress speed-to-lead from 20 minutes to 60 seconds. Free to start with consumption credits based on usage.