

Every AI model, agent, and workflow makes decisions based on the information it can see at the moment it's asked to act. If that information is thin, stale, or missing the surrounding facts that make it meaningful, the output is a guess dressed up as a recommendation.
Context data is the layer of situational information that turns raw data points into something an AI can actually reason on. This guide covers:
What context data is and how it differs from raw data and metadata
The four types of context data that matter most for B2B GTM
Where context data comes from and how it fits into the modern data stack
Why the GTM AI conversation has shifted from model quality to context quality
What Is Context Data
Context data is the situational information around an event, entity, or interaction that gives AI (and humans) enough understanding to act on it meaningfully. It's the difference between knowing that "user X clicked a pricing page" and knowing that "the VP of Engineering at a 3,000-person healthcare company clicked a pricing page after their team searched for competitor comparisons twice this week." The first is a raw event, while the second is a decision-ready signal.
Context data typically covers four dimensions:
Who the person or account is (role, seniority, company, size, industry)
What they're doing (behaviors, transactions, product usage, engagement)
When it's happening (recency, sequence, timing relative to other events)
Why it matters (fit against ICP, intent signals, comparison to typical patterns)
Without those layers, even the most sophisticated AI model is working blind, but with them, the same model can prioritize, personalize, and predict at a level that used to require a human analyst.
Context Data vs Raw Data vs Metadata
The terms get used interchangeably, but they describe three different things.
Type | What it is | Example |
Raw data | The base event or record itself | A form submission from john@acme.com |
Metadata | Descriptive information about the data | Timestamp, source, IP address, form ID |
Context data | The surrounding situational information that makes the data meaningful | Acme is a 500-person SaaS company in the ICP, John is their VP of Sales, three other Acme employees visited the site this week |
Raw data tells you something happened, metadata tells you where and when, and context data tells you what it means. AI models can process all three, but they only produce useful output when the context layer is complete.
The Four Types of Context Data in B2B GTM
In a go-to-market setting, context data breaks down into four categories, each answering a different question about an account or contact. Together they combine structured records (firmographic, technographic) with unstructured data pulled from conversations, emails, and web activity. That mix is what gives modern AI agents a full view of every account.
Type | What it captures | Common sources |
Firmographic | Company-level attributes: industry, size, revenue, location, hierarchy | Business databases, public filings, verified B2B data providers |
Technographic | The technologies a company uses, including CRM, marketing stack, cloud infrastructure | Web scraping, install tracking, self-reported data |
Behavioral | Actions taken by people at the account, from site visits to product usage to email engagement | First-party analytics, CRM activity, product telemetry |
Intent | Signals that an account is researching your category or competitors elsewhere on the web | Intent data providers, review site activity, content consumption networks |
Elite GTM teams combine all four to build a full picture of every account, because any one of these in isolation is incomplete. A firmographic match tells you an account fits the ICP, while technographic data tells you whether they're already running a competitor. Behavioral data captured through website visitor tracking shows what they're doing on your properties, and intent data reveals what they're doing everywhere else. Together, they're what makes AI-powered prioritization, routing, and personalization actually work.
Why AI Depends on Context Data
The AI trust problem in B2B doesn't come from bad models. It comes from bad context. Generative AI systems and machine learning models are only as reliable as the information they're grounded in. The gap between a plausible-sounding output and the right output almost always traces back to the context layer.
An LLM can generate a perfectly written outbound email, but if it doesn't know the recipient just changed jobs, works at a company that already churned from your product, or sits three levels below the actual buyer, that email lands as noise. The model didn't hallucinate. It just didn't have the context to know better.
This is why the AI conversation has shifted toward grounding. Grounding an AI model with verified context data does three things:
Reduces hallucination by anchoring outputs to real, current information instead of the model's training-time priors
Improves relevance by shaping recommendations around the specific account, contact, or moment rather than a generic average
Enables autonomous action by giving AI agents the situational awareness to act without a human double-checking every step
None of this works without a foundation of accurate, current context data, and in B2B "current" matters a lot. Roughly 70% of contact data goes stale annually as people change jobs and companies restructure. Context data that's six months old is often actively misleading, which is why continuous data enrichment rather than batch refreshes is what keeps the context layer from decaying under the AI stack.
How Context Data Reaches AI Agents at Runtime
Understanding why AI needs context data is one thing. Getting that context into the model at the moment it's making a decision is another, and it's where most GTM AI pilots break down.
Three mechanisms move context data from the source layer into an AI system's working memory:
Retrieval-augmented generation (RAG). The most common pattern for large language models. When a user or agent triggers a task, the system queries the context layer for relevant records and injects them into the prompt before the model generates a response. RAG is why an LLM drafting outbound can reference a prospect's actual role, company size, and recent activity rather than inventing plausible-sounding details.
Tool calls and function invocation. Agents can call context APIs directly during a task, pulling specific fields on demand (a job title, a technographic match, an intent score) instead of receiving the full record upfront. This works well for multi-step workflows where the agent needs different context at different stages.
Streaming feedback loops. Once an agent acts, the outcome (email opened, meeting booked, deal lost) feeds back into the context layer, updating account-level records that the next agent will use. When feedback loops close cleanly, the system gets sharper over time. When they break, the same errors get scaled.
The mechanism matters less than the underlying requirement. Whichever pattern a team uses, the context data reaching the model has to be current, resolved to the right entity, and delivered fast enough to influence the decision. Miss any of those three and the pattern breaks. That's why so many GTM AI pilots stall after the first deployment.
How Context Data Powers Modern GTM Workflows
Context data isn't a nice-to-have for a handful of AI use cases. It's the underlying layer that makes almost every modern GTM workflow function.
Lead scoring and prioritization. Predictive lead scoring models rank inbound leads by combining fit context (firmographic match to ICP) with behavioral context (engagement patterns) and intent context (external research signals). Without those layers, lead qualification collapses to guesswork.
Personalization at scale. Personalized outbound only works when the AI generating the message knows what the recipient's company does, what their role is, and what problem they're likely to care about. Generic personalization tokens don't count.
Lead routing. Intelligent routing sends leads to the right rep based on firmographic fit, sales territory, seniority, and account ownership rules, and every one of those is context data.
Forecasting. Sales forecasting improves dramatically when models have context on account health, buyer group changes, engagement trajectory, and comparable historical deals.
Agent orchestration. AI sales agents that research accounts, draft outreach, or manage handoffs need context data at every step, or they act on whatever fragmentary picture their prompt happens to include.
Churn and expansion prediction. Predicting which customers will renew, expand, or churn requires context on product usage, engagement patterns, and firmographic changes like acquisitions or leadership shifts.
The through-line across all of these is the same. Context data is what separates AI that sounds right from AI that is right.
Where Context Data Comes From
Context data comes from three broad source categories, and most GTM teams have to assemble it from all three.
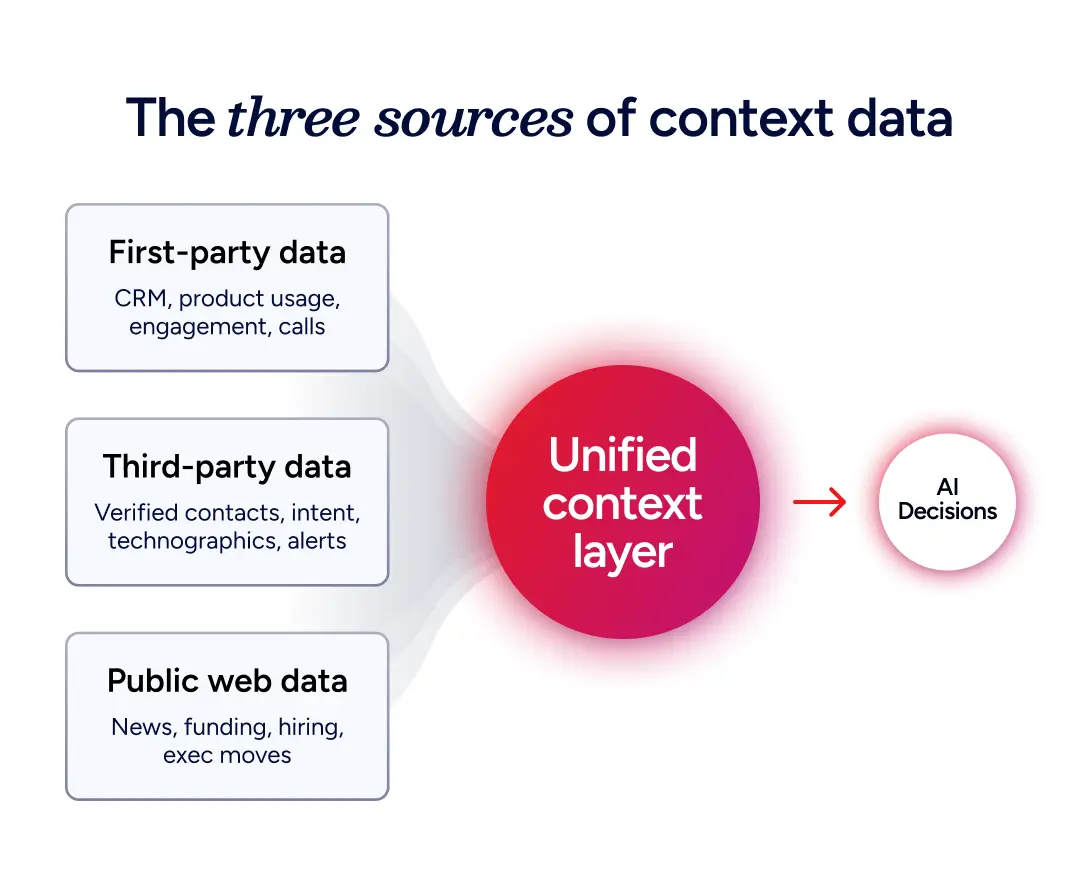
First-party data is information the company owns and generates itself: CRM records, product usage, email engagement, website visits, sales conversations, and support tickets. These systems of record and internal knowledge bases give high-fidelity context for accounts already in the system but leave everyone else invisible.
Third-party data comes from external providers and covers the accounts and contacts first-party sources don't reach. Verified B2B data providers, intent networks, technographic targeting services, and job change alerts all sit in this category. Together they fill in the parts of the market map that first-party data can't see.
Public web data covers what's observable on the open web: news, funding announcements, product launches, executive moves, and hiring signals. It provides real-time context that neither first- nor third-party sources catch quickly enough on their own. That's why the fastest-moving GTM teams treat public web data as a distinct third input rather than folding it into third-party.
Teams that get the most out of AI aren't the ones with the most data in any single category. They're the ones who unify all three into a single coherent view of each account and contact through master data management and consistent schema design.
Where Context Data Fits in the Modern Data Stack
Context data doesn't live on its own. It sits on top of the systems most GTM teams already run, and understanding where it fits helps explain why so many teams struggle to operationalize it.
Traditional data infrastructure moves data from source systems into data warehouses or data lakes, where analytics tools and BI dashboards query it for historical reporting. That architecture is optimized for structured queries and periodic analysis, not for the split-second decisions AI agents make while a workflow is running. Context data requires something different: a semantic layer that resolves entities across sources, tracks data lineage from origin to output, and delivers the resulting intelligence to any application, agent, or workflow that asks for it.
This is where standards like the Model Context Protocol (MCP) come in. MCP defines how AI agents pull context from external systems without custom integrations, so a well-designed context layer can serve verified intelligence to any MCP-compatible tool. The shift matters because it decouples context data from any single application. That means the same source of truth can power your CRM strategy, your outbound tool, your forecasting model, and any custom agent your team builds.
The best-run GTM data ecosystems now treat context data as a distinct product on top of the warehouse rather than another dashboard fed by it. That's the architectural shift making enterprise AI usable in production.
The Challenges of Managing Context Data
Context data is powerful when it works, but the operational challenges are real.
Freshness. Context decays fast. People change jobs, companies restructure, technographic stacks shift, and intent signals expire within days, which is why data hygiene practices matter as much as data acquisition.
Entity resolution. The same person and the same company show up under different names, spellings, and identifiers across dozens of systems. Without reliable deduplication and entity resolution, context data fragments across duplicate records and never gets fully assembled.
Unification across sources. First-party, third-party, and public web data live in different systems with different schemas and different update cadences. Making them queryable as a single intelligence layer requires infrastructure most GTM teams don't have, and breaking down data silos is often step one.
Data governance and access controls. As context data spreads across tools and agents, governance becomes a first-order concern. Who can query what, which records are permitted for automated decisions, and how sensitive customer data is protected all shape whether the context layer is trusted or bypassed.
Data lineage and provenance. When an AI recommendation is wrong, the fix requires tracing which piece of context data caused the error. Without lineage tracking that follows each field from source system to final output, debugging AI decisions turns into guesswork.
Data quality controls. Poor data quality at any layer propagates into every downstream AI decision. Teams building serious context infrastructure invest in continuous CRM hygiene and validation rules from day one.
Data privacy and compliance. Privacy regulations impose real limits on which context data can be collected, stored, and used in automated decisions. Mistakes here carry legal and reputational cost.
These challenges are why context data has become a category of its own in the GTM tech stack rather than a subset of CRM or marketing automation. Managing context at the scale AI requires is a distinct discipline.
How ZoomInfo Delivers Context Data for B2B GTM

Context data only produces reliable AI output when it's unified, current, and connected to the workflows that use it. That's what ZoomInfo built.
Verified B2B data at scale. ZoomInfo maintains 500M+ professional profiles, 100M+ companies, and 135M+ direct dials, refreshed through 1.5B+ data points processed daily. The firmographic, technographic, and contact context feeding your AI stays current instead of stale.
The GTM Context Graph. A unified context graph that fuses ZoomInfo's third-party data with your first-party engagement history and product usage signals. Every AI decision runs on a full picture rather than a fragment.
Universal access through GTM.AI. ZoomInfo's headless context engine delivers verified intelligence to any AI model, agent, or workflow through APIs and MCP integrations. The same context powers GTM Workspace for sellers, GTM Studio for marketers and RevOps, and any custom agent your team builds.
For GTM teams, that means the context data your AI stack depends on comes from one source and reaches every tool that needs it.
The Bottom Line on Context Data
Context data isn't a differentiator you invest in once. It's infrastructure you maintain continuously, because every AI decision your team makes tomorrow depends on what's in that layer today. The teams treating it as a permanent priority are the ones getting real ROI from GTM AI.
Talk to our team to see how ZoomInfo delivers the context data your AI stack needs to prioritize, personalize, and act with confidence.
Frequently Asked Questions
What Is Context Data?
Context data is the situational information around an event, entity, or interaction that gives AI (and humans) enough understanding to act on it meaningfully. In B2B, it typically includes firmographic, technographic, behavioral, and intent data that surrounds every account and contact.
What's the Difference Between Context Data and Metadata?
Metadata describes the raw data itself (timestamps, sources, format), while context data describes the situation around it (who the person is, what company they work for, what they're likely trying to accomplish). Metadata answers where and when, whereas context data answers what it means.
Why Does AI Need Context Data?
AI models make decisions based on the information available at inference time, so without context data they fall back on generic patterns from their training data, which produces plausible-sounding but often wrong output. Context data grounds AI in the specific situation, which reduces hallucination and improves relevance.
What Are Examples of Context Data in B2B?
Common examples include company size, industry, and revenue (firmographic); the software a company uses (technographic targeting); pages visited, emails opened, and product features adopted (behavioral); and research activity on external sites (intent).
How Is Context Data Collected?
Context data comes from three main sources: first-party systems the company owns (CRM, product analytics, engagement platforms), third-party providers (data enrichment services, intent networks, buyer intent tools), and public web sources (news, filings, hiring signals). Most GTM teams assemble context data from all three.